notacja commitów - jak dwa proste pytania zrewolucjonizują twoją pracę
[Zobacz słownik używanych pojęć]
Największa zmianą w moim stylu pracy było przyjęcie notacji commitów opartej na dwóch pytaniach:
- jakiego typu jest ta zmiana?
- jak duże ryzyko wnosi?
To sprawiło że praca stała się prostsza, szybsza, bezpieczniejsza i dająca większą satysfakcję.
1. jakiego typu jest ta zmiana?
W notacji możemy zawrzeć masę informacji ale najważniejszą jest typ zmiany. Jakiego typu może być zmiana?
| typ zmiany | opis zmiany |
|---|---|
| feat | A new feature |
| fix | A bug fix |
| docs | Documentation-only changes |
| style | Changes that do not affect the meaning of the code, such as changes to whitespace, formatting, missing semicolons, and so on |
| refactor | A code change that neither fixes a bug nor adds a feature |
| perf | A code change that improves performance |
| test | Changes that add missing tests |
| chore | Changes to the build process or auxiliary tools and libraries, such as documentation generation |
| remove | Changes that involve removing something from the codebase (ten typ dodałem sam) |
Jeśli zaczniemy określać typ każdej zmiany, commita to stanie się kilka rzeczy:
- przestaniemy mieszać ze sobą różne typy zmian, zaczniemy tworzyć commity jednego, góra dwóch typów
- zmniejszy się rozmiar commita co ułatwia ich przegląd i integrację
- zwiększy się nasze skupienie, skupiamy się tylko na jednym typie zmiany, na jednym celu który chcemy osiągnąć. Nie rozpłyniemy się myślami i czynnościami w innym kierunku
- zwiększy się nasza satysfakcja z pracy. Praca zostanie podzielona na kilka mniejszych checkpointów, a po osiągnięciu każdego z nich będziemy mogli głośno obtrąbić nasz sukces!
- zwiększy się bezpieczeństwo pracy i obniżymy ryzyko wystąpienia błędu
- wymusi to chęć częstszej integracji - Continuous Integration (CI)
- zachęci to nas do robienia drobnych poprawek - refactorings!
- stworzymy szczegółową dokumentacje dotyczącą zmian w projekcie
- otworzy się furtka do takich technik jak 'read by refactoring'
Jak widać warto, warto. Ale równie dobrze mógłbym wypisać zalety codziennych ćwiczeń fizycznych. Wszystko fajnie ale jak to wprowadzić, żeby ludzie chcieli z tego korzystać?
Na notacje bezpośredni wpływ ma sposób integracji kodu. Notacja i integracja są ze sobą ściśle powiązane i wzajemnie na siebie oddziałują. Ważniejsza jest notacja, bo jest pierwsza: wpierw opisujemy zmiany, następnie integrujemy kod. Więc jeśli wyjdziemy od notacji to sposób integracji kodu zostanie naturalnie wymuszony.
Natomiast działa to też w drugą stronę, jeśli jeszcze nie opisujesz typu zmian to zapewne korzystasz ze sposobu integracji kodu zwanego 'feature branch' i to przez niego masz trochę wymuszoną notacje: 1 commit = 1 ticket. Przyjrzyjmy się więc sposobom integracji kodu.
2. feature branch
Tworzę nowy branch z gałęzi, która jest stabilna, np. master i na nim wprowadzam zmiany. Dopiero kiedy skończę, integruję go z masterem. Może zawierać kilka commitów albo jeden. Często w momencie integracji te kilka commitów jest łączonych w jeden przez opcję 'squash commits in a merge request'.
2.1. zalety
- master nie zawiera niedokończonych ficzerów, kodu 'in-progress'
- czysta i prosta historia commitów, nowych ficzerów
- pozwala łatwo wycofać dany ficzer - 'revert commit'
- wymusza tworzenie małej liczby commitów
2.2. wady
- im dłużej trwają pracę na takim wyizolowanym branchu tym więcej
dodatkowej pracy musimy poświęcić na integracje z masterem
- aby zmniejszyć problem często w trakcie prac aktualizujemy nasz branch z masterem
- nie widzimy codziennych stopniowych zmian, tylko duże zmiany przy integracji
- kiedy mam kilka branchy których zmiany dotyczą tych samych obszarów, to ich późniejsza integracja stwarza potworne problemy
- duże skomplikowane, problematyczne MR
Ale najpoważniejszą wadą są problemy z refaktoringiem, pracami porządkowymi, przygotowującymi do właściwej zmiany. Co sprawia, że często ten rodzaj prac jest porzucany bo najzwyczajniej tutaj nie pasuję, tworzy wiele konfliktów, dodaje za dużo szumu, sprawia problemy.
2.2.1. problemy z refaktoringiem
Sądzę, że nie da się całkowicie uniknąć refaktoringu. W miarę jak problemy się nawarstwiają, będziemy zmuszeni je rozwiązać.
Problemy to narastające trudności w pracy, spowolnienie jej tempa, liczne błędy wynikłe z braku przejrzystości i czytelności kodu, coraz więcej czasu potrzeba na 'utrzymanie', naprawy rzeczy bieżących, niskie morale i duża niechęć do pracy.
Czasem mogą pojawić się pomysły na wygospodarowania większej ilości czasu zarezerwowanego tylko na refaktoring a raczej bardziej remodeling i posprzątaniu wielkiego bałaganu. To tak jak ze zdrowiem, albo dbamy o nie codziennie, albo raz na jakiś czas jesteśmy zmuszeni do zajęcia się nim i podreperowania. Nie ma tutaj ucieczki.
Jakie mamy możliwości, strategie kiedy chcemy uwzględnić taki rodzaj prac?
- robimy refaktoring raz na jakiś czas
Jako całkowicie odrębne zadania a nawet cały sprint z odrębnymi zadaniami. Próbujemy wygospodarować osobny wyznaczony czas na refaktoring. Ale rzadko spotyka to się ze zrozumieniem ze strony managementu. Sytuacja pogarsza się, gdy musimy wprowadzić to w korporacyjne metody agile i oszacować czas realizacji.
Refaktoring to małe inkrementalne zmiany a wygospodarowania większej ilości czasu to raczej grubsze próby przemodelowania całej aplikacji.
- robimy refaktoring codziennie i…
- nie określamy typu każdej zmiany (commita) i robimy jeden duży MR
Tworzy to gigantyczne MR gdzie wymieszane są różnego typy zmiany. Koszmarnie się to przegląda, brak precyzyjnej informacji czego dotyczą zmiany. Zmiany niskiego ryzyka wymieszane są ze zmianami wysokiego ryzyka, jest ich po prostu za dużo. Takie MR powinno zostać bezwzględnie odrzucone.
- określamy typ każdej zmiany (commita) i robimy jeden duży MR
Wydzielenie każdej zmiany to bardzo duży postęp. Jednak z uwagii, że wszystko jest w jednym MR to rzadko kiedy każdy commit jest odpowiednio wyizolowany, atomiczny, żeby w razie wątpliwości zintegrować tylko te wybrane. Powoduję do gwałtowny wzrost i tak już dużego ficzer brancha. Ale możemy osobno przejrzeć wydzielone commity.
- określamy typ każdej zmiany (commita) i każdy typ puszczamy jako osobny, mały MR albo w paczkach
Myślę, że to najrozsądniejsze podejście. Oczywiście będziemy musieli zwiększyć częstotliwość integracji, ale zgodnie z podejściem 'feature branch' cały osobny ficzer puścimy tradycyjnie na koniec jako jeden commit, a codziennie będziemy integrowali tylko drobne zmiany. Sądzę, że jest to okres przejściowy, ale nadal potrzebny, aby zmiana podejścia i przyzwyczajeń przebiegła w miarę przyjemnie i płynnie.
Zwiększy to czas potrzebny na 'code review', ale możemy umówić się w zespole, że pewne zmiany, które niosą niskie ryzyko, jak zmiany stylu, formatowania czy też automatyczne przekształcenia IDE, mogą być z automatu integrowane. Czyli pewna praca przygotowawcza niskiego ryzyka jest integrowana od razu, albo codziennie wystawiana jako MR, a zespół rano ma przeznaczyć np. 30 min na integrację, a my pracujemy dalej nad danym ficzerem. Więc siłą rzeczy musimy zwiększyć częstotliwość integracji.
Integrujemy drobne zmiany, a cały czas staramy się utrzymać 'feature branch', który składa się z głównych, zaplanowanych zmian w tickecie. Wymuszamy częstszą integrację, ale tylko z drobnymi zmianami. Owy ficzer cały czas jest oddzielnym, całościowym branchem. Krok dalej to rozbicie go na mniejsze części i zwiększenie tempa integracji, czyli 'continuous integration (CI)'.
- nie określamy typu każdej zmiany (commita) i robimy jeden duży MR
3. continuous integration (CI)
Przeciwieństwem 'feature branch' jest podejście Continuous Integration (CI). W którym codziennie integrujemy małe zmiany do mastera. Jeśli dodajemy jakiegoś ficzera to kod dzielimy na mniejsze porcję i dopóki całość nie zostanie skończona to ficzer jest wyłączony poprzez 'feature toggle'.
Małe, drobne zmiany to kwintesencja refaktoringu. Więc 'CI' tworzy idealne warunki dla tego typu działań.
4. porównanie feature branch vs. continuous integration (CI)
| feature branch | continuous integration | |
|---|---|---|
| commit: wielkość | duży | mały |
| commit: typ | brak rozróżnienia na typy, albo 1 typ ficzer | wiele typów |
| commit: ilość | mała, zazwyczaj 1 ticket = 1 commit | bardzo duża |
| integracja: kiedy? | rzadko, bardzo problematyczna, czasochłonna | codzienna, prosta, szybka |
| integracja: jak? | całościowa, dopiero kiedy ficzer jest gotowy | fragmentaryczna, po kawałku, codziennie |
| refaktoryzacja | bardzo problematyczna, trudna, zniechęcająca | bardzo prosta, łatwa, zachęcająca do zmian |
| ryzyko błędu | wysokie, trudne do wykrycia i naprawienia | niskie, łatwe do wykrycia i naprawienia |
| code review | trudne, czasochłonne, skomplikowane | duża ilość commitów ale są proste, małe, jednorodne |
Myślę, że rysunek poniżej dobrze oddaje style pracy który porównujemy.
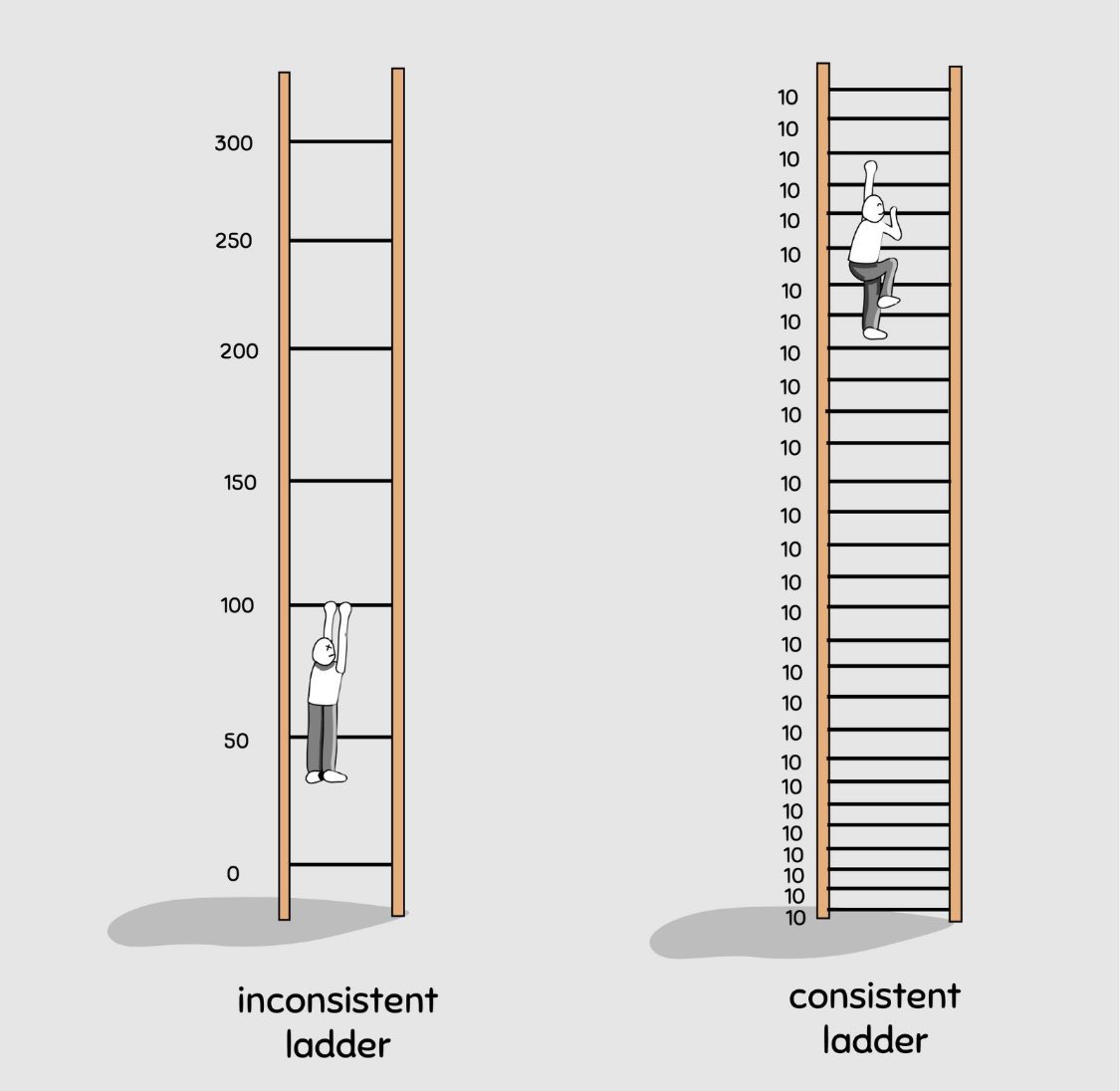
Albo robimy duże zmiany i rzadko je integrujemy albo małe zmiany i często je integrujemy.
5. jak zacząć oznaczać typ commita?
Zacząłbym od najprostszych typów i wprowadzał stopniowo. Zapewne każdy oznacza 'feature' i 'fix', dodałbym do tego 'style' i 'refactor'.
5.1. style
Powszechnie wszyscy wiemy, aby nie mieszać zmian logiki oraz formatowania. Wybitnie zmniejsza to czytelność, czasem wręcz uniemożliwiając zrozumienie istoty zmian i jest podstawą do całkowitego odrzucania MR.
Powszechne narzędzia z których korzystamy (Git, Github, PHPStorm) nie rozróżniają typu zmian tylko wskazują linie w której zaszła dana zmiana nie wnikając w strukturę kodu.
Na przykład poniżej mamy prostą funkcję która z uwagii na brak wcięcie jest trochę 'nieczytelna', 'nieprzyjemna'.
function greet($name) {
echo "Hello $name";
}
Wystarczy dodać wcięcie.
function greet($name) {
echo "Hello $name";
}
Jednak w diffie podświetlona będzie cała linia. Trzeba się przyjrzeć, zastanowić, może coś w 'Hello' się zmieniło, albo nazwa zmiennej. Musimy przyjrzeć się całej podświetlonej linii.
function greet($name) {
-echo "Hello $name";
+ echo "Hello $name";
}
Dlatego oznaczenie typu zmiany [style] od razu dostarcza nam informację bez wnikania i czytania diffa, że zmiana dotyczy tylko i wyłączenie stylu formatowania. Dodatkowo oznaczenia stopnia wnoszonego ryzka 0. Daje jasny komunikat, że jest to absolutnie bezpieczna zmiana.
5.2. refactor
Opieramy się tutaj tylko na 'automatycznych przekształceniach' oferowanym przez IDE (np. PHPStorm) chodzi głównie 'refactorings': rename, inline, extract. Nie robimy nic manualnie, bo możemy się pomylić i wprowadzić błąd. Zaczęcie stosowania tego typu umożliwia zastosowania techniki 'read by refactoring', która jest niezwykle pomocna w pracy z kodem trudnym jak np. 'legacy code'.
6. read by refactoring
Dosłownie 'czytanie przez refaktoryzację'. Naszym celem jest zrozumienie kodu i aby to osiągnąć czytamy go jednocześnie poddając 'automatycznym przekształceniom' oferowanym przez IDE (np. PHPStorm) chodzi głównie 'refactorings': rename, inline, extract.
Czytając kod wprowadzamy do niego małe inkrementalne zmiany, które polepszają jego czytelność i strukturę. Co pozwala nam na szybsze, dokładniejsze i głębsze zrozumienie. Nie są to zmiany dotyczące zmiany zachowania kodu, lecz tylko te dotyczące nazewnictwa i struktury.
Myślę, że tutaj ten sposób można rozbić na dwa podejścia:
6.1. uwzględniamy wszystkie wykonane zmiany
Czyli każdą zmianę którą wykonamy robimy z zamiarem, że dołączymy ją do mastera. Aby mieć pewność, że zmiany nie niosą żadnego ryzyka korzystamy tylko z 'automatycznych przekształceń'. Nie możemy sami 'manualnie' zmieniać kodu bo niesie to ryzyko błędu.
6.2. nie uwzględniamy wszystkich zmian, tylko niektóre
Tutaj wykraczam poza bezpieczne i automatyczne przekształcenia IDE. Więc wprowadzamy ryzyko, które może doprowadzić do błędu. Moim celem jest tutaj uporządkowanie kodu tak jak mi się podoba, co ma pozwolić na jego szybsze i głębsze zrozumienie. Dopiero na podstawie uzyskanej wiedzy, insightu tworzę nowy branch i czasem przenoszę niektóre commity, które uważam, że są bezpieczne i wartościowe.
Poniżej przykład takiej zabawy:
6.2.1. przykład zastosowania dla trudnego kodu
Kod był dla mnie trudny, ponieważ był napisany w języku, w którym mam mało doświadczenia - elisp. Tutaj link do repozytorium: org-colview.
Pierwszy commit dotyczył zmiany komentarza nad funkcją - usunięcia przedimka 'the'. Tylko tyle. Ale to pozwoliło mi usunąć coś, co mi nie pasowało, i trochę rozgościć się na nowym terenie. Znaleźć ten pierwszy przyczółek, z którego można zacząć abordaż.
W drugim commicie poprzenosiłem funkcje, tak aby te jednego typu były blisko siebie - zmniejszając pomiędzy nimi odległość pionową, grupując funkcje wzajemnie się wywołujące, więc czytane razem. W trzecim commicie przekształciłem funkcję na 'pure function', usuwając z niej zmienną globalną. Później posortowałem alfabetycznie funkcje i tak dalej.
Niektóre zmiany zostały później wprowadzone, ale zdecydowana większość nie.
Te zmiany niekoniecznie muszą być ostatecznie wprowadzone. Przyznam, że jeśli mam bardzo skomplikowany kod, którego nie znam, to wprowadzam do niego bardzo dużo zmian podczas czytania kodu - zmieniając formatowanie, zmieniając nazwy elementów systemu, które niekoniecznie są poprawniejsze. To decyzje podejmowane przy pierwszych nieśmiałych próbach poznania i zrozumienia systemu, a nie na podstawie jego głębokiej znajomości. Zapewne te nowe nazwy zmiennych w całym kontekście mogą nie być lepsze, ale w tym konkretnym przypadku, kiedy zaczynamy czytać, pozwalają lepiej zrozumieć, zbudować sobie pewien obraz, model mentalny, z jakich elementów składa się aplikacja i jak działa. Chodzi o to, aby ruszyć z miejsca.
Często miałem tak, że bardzo długo czytałem kod, próbując go zrozumieć i jego powiązania, ale nic absolutnie nie zmieniałem, bo się po prostu bałem. To jednak kompletnie utrudnia zrozumienie. Postawienie danego obszaru do testów byłoby niezwykle trudne i czasochłonne. Nie czekajmy aż poznamy i zrozumiemy kod na tyle dobrze, że będziemy mieli pewność co do wprowadzanej zmiany. Po to mamy system kontroli wersji Git, abyśmy nie obawiali się zmian.
To podobnie jak z rysowaniem. Rysunek wyłania się z drobnych szkiców, ołówkiem, nie stawiamy od razu głównych linii, które są perfekcyjne. Te linie główne, właściwe, wyłonią się same z kilkudziesięciu innych pociągnięć ołówkiem.
7. jak duże ryzyko wnosi ta zmiana?
Korzystając z oznaczania danego typu brakowało mi jeszcze jednej rzeczy. Jako, że głównie pracuję z 'legacy code'. Patrząc na historię typ commita określa na które zmiany warto zwrócić uwagę, a które możemy pominąć w przeglądaniu. Rzeczy które zawsze możemy pominąć to np. te dotyczące stylu, czyli zmiana formatowania, usunięcie whitespace itp. Dlaczego możemy je pominąć? Ponieważ nie zmieniają zachowania kodu, ani nie ingerują w jego strukturę jak np. refaktoring. Więc tym samym są zmianą bezpieczną czyli taką która nie wnosi żadnego ryzyka. Ryzyko to właśnie to czego mi brakowało.
Które zmiany są na tyle ryzykowne, że powinny zwrócić uwagę? Samo wymuszenie ustalenia ryzyka, próby przypisania i określenia jakie ryzyko wnosi dana zmiana powoduję, że musisz się nad tym zastanowić. Jeśli sądzisz, że ryzyko zmiany jest duże, może warto je zmniejszyć dodając testy albo dzieląc zmiany na mniejsze fragmenty. To wprowadza dodatkowy checkpoint do zadumy i zastanowienia się nad intencja i ryzykiem zmiany.
Znalazłem już istniejącą notację Arlo's Commit Notation ale uważam, że jej zapis jest trochę enigmatyczny bo do oceny ryzyka używa liter i znaków interpunkcyjnych. A sadzę, że do oceny ryzyka idealnie nadają się cyfry od 0 do 3 bo od razu widać gdzie ryzyko jest większe bądź mniejsze. Poniżej próba opisania możliwych ryzyk z notacji Arlo:
| Risk Number | Risk Level | Meaning | Correctness Guarantees |
|---|---|---|---|
| 0 | Known safe | Addresses all known and unknown risks. | Intended Change, Known Invariants, Unknown Invariants |
| 1 | Validated | Addresses all known risks. | Intended Change, Known Invariants |
| 2 | Risky | Some known risks remain unverified. | Intended Change |
| 3 | (Probably) Broken | No risk attestation. |
- 0 - daję z automatu każdej zmianie dotyczące stylu [style] oraz testom [test].
- 1 - większość rzeczy które nie mają testów, więc to najpopularniejsze ryzko
- 2 - obowiązkowo daje każdej migracji
- 3 - czasem zdarza mi się, że jestem w trakcie pracy i muszę ją przerwać, więc szybko daję 3 i piszę 'WIP' abym np. następnego dnia do tego zasiadł był świadomy, że zostawiłem stan niedziałający
Przykładowa historia commitów z projektu który był stawiany od nowa - to proste API:
0 [feat][test] testMeetingShouldNotBeLongerThanEightHours
0 [refactor] CustomKernelTestCase->createUser - provide default values
0 [test] testMeetingOwnerShouldAlwaysBeThePersonWhoCreateTheMeeting
1 [feat] User has a password - authorization
1 [refactor] Meeting owner req in constructor
0 [refactor] fix Meeting relations with User
0 [refactor][rename] MeetingTest -> MeetingListingTest
0 [test] add testSearchByRoomName
0 [refactor] createMeeting now takes Room params for input
0 [test] add testShowDetailsOfRoomWhenListingMeetings
0 [test][fix] add RoomFactory
1 [feat] add Entity\Room
0 [test] add testSearchByStartDay
0 [refactor] MeetingTest, add CustomKernelTestCase
0 [test] add testSearchMeetingByAgenda
1 [test] MeetingTest update
0 [chore] composer req zenstruck/browser
1 [fix] Meeting.owner not ownerId, should be ManyToOne
1 [chore] add phpunit, first MeetingTest
1 [feat] add Entity/Meeting
0 [remove] dir /migrations
1 [chore] composer req foundry orm-fixtures --dev
0 [docs] User api annotation
0 [chore] composer req debug
2 [feat][migration] add User entity
0 [chore] composer req maker --dev
0 [chore] composer req api
0 [chore] symfony new
Add initial set of files
8. podsumowanie
Wprowadzenie notacji commitów opartej na dwóch pytaniach - "jakiego typu jest ta zmiana?" i "jak duże ryzyko wnosi?" - oraz dostosowanie stylu integracji kodu do tych wytycznych okazało się przełomem w moim codziennym podejściu do pracy.
Mam nadzieję, że przedstawione podejście pomoże Wam w codziennej pracy i uczyni ją bardziej efektywną oraz satysfakcjonującą. Zachęcam do eksperymentowania z różnymi metodami i dostosowywania ich do specyfiki Waszych projektów oraz zespołów. Powodzenia!
9. polecane artykuły
10. słownik
- używam terminu Merge Request (MR)
- Pull Request (PR) - oznacza to samo tylko jest używany w GitHub i Bitbucket a MR na GitLabie
- używam zamiennie terminów 'commit' i 'zmiana/y'
- używam zamiennie terminów 'branch' i 'gałąź'
- integracja to merge do master'a